
The Ultimate Guide to CI/CD for Data Engineering in Databricks
Fundamental Data Engineering Challenges and How to Address Them in Databricks

Continuous Integration and Continuous Deployment (or Delivery) — CI/CD — are DevOps practices designed to enable fast, reliable, and predictable feature development. As developers, we want to have a system in place that allows us to develop, extend, and roll out changes to data pipelines without interfering with running systems, while also avoiding manual errors.
However, in the world of data engineering, particularly with platforms like Databricks, applying these principles presents unique challenges compared to traditional software development. In this article, we will explore the necessary tools, best practices, and challenges involved in designing a data engineering development workflow for Databricks.
Even though we will present the current state of the technical implementation, we will also cover some of the theoretical considerations and facts we need to keep in mind:
The final product of a data pipeline isn’t the pipeline code itself, but the dataset it produces.
A pipeline must either work end-to-end with all the required data for the final product, or it doesn’t work at all.
CI/CD in data engineering needs to account for the interdependence between code, data, and compute, which complicates testing and deployment.
Data pipelines must integrate multiple systems and manage complex stateful processes, making them harder to test and maintain than stateless applications.
Data pipelines cannot be developed in the same iterative and collaborative manner as traditional software products.
Introduction to CI/CD in Data Engineering
CI/CD pipelines should automate the build, test, and release processes, minimizing human intervention and reducing the risk of potential errors. While CI/CD has been widely adopted in traditional software development, its application in data engineering requires practical adaptation due to the fundamental differences between the two domains. You can explore these differences in one of my favorite articles here: Data Engineering is Not Software Engineering
Challenges of Implementing CI/CD in Data Engineering
Data engineering involves building data pipelines that process large volumes of data, integrate multiple systems, manage complex data states, and often require sophisticated orchestration to achieve the desired outcomes.
These pipelines are not just about code; they encompass data transformations, storage, and movement across various environments. Therefore, standard software CI/CD patterns need to be adapted to suit the requirements of data engineering solutions. In contrast to traditional software development there are several major differences that create challenges:
Interdependence of Code, Data and Compute: In traditional software development, code can often be tested in isolation using mock inputs or small datasets. However, in data engineering, pipelines rely heavily on data, which means the code’s correctness often depends on the data it processes and the compute environment where it runs. Testing must therefore account for the real-world data or a representative subset, and the right configuration of compute resources (such as clusters, memory, and storage). Without these, it becomes difficult to validate the code’s behavior, as it could pass in development but fail with actual data or under different compute conditions.
This creates complexity in CI/CD for data pipelines, as testing environments need to closely resemble production, and proper orchestration (and governance) is required to handle the dependencies between code, data, and the compute environment.
Complex System Integration: Data pipelines interact with multiple systems, such as databases, cloud storage, APIs, and third-party services. Even if the pipeline code and logic are correct, the integration points between these systems introduce additional layers of complexity. A failure in one system (e.g., an API being down, a database connection issue, or data schema changes) can cause the entire pipeline to fail, even when the code itself is error-free.
This complexity makes it challenging to implement CI/CD, as it requires testing not only the code but also the interactions between various systems to ensure they work together correctly under different scenarios and configurations.
State Management: In data engineering, pipelines must stay in sync with the state of the data they process. Unlike stateless applications, which can easily restart without depending on previous states, data pipelines often rely on specific data stages or checkpoints. For example, when processing large datasets in batches, the pipeline must track where it left off to avoid reprocessing or missing data.
This presents challenges for CI/CD pipelines, as they must maintain data flow continuity when migrating between environments. Furthermore, testing also becomes more complex since we have to test the data as it is being processed through different states.
Evolution of Data Engineering CI/CD Practices
Over the past few years, we have seen many companies struggle to design and implement CI/CD for their data solutions for several reasons:
Absence of Standard Practices: The data engineering field has long lacked universally accepted standards for CI/CD. With no clear guidelines, many organizations were left to build their own solutions, often resulting in processes that were either overly complex or too simplistic.
Limited DevOps Expertise: Data engineering teams frequently lacked the DevOps knowledge needed to design and implement effective CI/CD pipelines. When they had DevOps skills, the unique demands of data engineering meant that traditional CI/CD models didn’t translate seamlessly, leaving teams unsure of how to structure their pipelines.
Limited Vendor Capabilities: Managed platforms provided some tools to enable CI/CD processes, but early implementations often felt cumbersome. These solutions were more like workarounds than fully integrated, reliable systems for automating data engineering workflows.
As the data landscape evolved, so did the need for scalable and flexible development processes. The shift from traditional data warehouses to data lakes and lakehouses, from structured data to “big data,” and from ETL to ELT made clear that the CI/CD approaches from software engineering wouldn’t work in data engineering. Instead of just managing code, data engineers needed to handle massive datasets in distributed environments, often using a combination of different programming languages and orchestration tools. The interdependencies between data, code, and compute resources meant that pipelines couldn’t be treated in isolation, and testing required a realistic representation of production data, adding layers of complexity.
Vendors, including Databricks, responded to these challenges by iterating on their tools to better support data engineering CI/CD practices. The introduction of features like Databricks Repos (for better version control integration) and more robust API and CLI tools helped bring more structure and reliability to the process. With these new tools came increased flexibility, allowing data teams to better organize their code and pipelines while automating deployments and testing more effectively.
Today, while there is still no single “best” way to implement CI/CD for data engineering, the landscape has matured significantly. Companies now have access to a growing suite of tools and practices that make the process more reliable, scalable, and streamlined.
CI/CD for Databricks
A CI/CD pipeline automates the movement of code and assets from one environment to the next, performing tests along the way to ensure everything functions correctly. Once all tests pass, the pipeline deploys the assets to production. While the specifics can vary, the core components of this process stay the same:
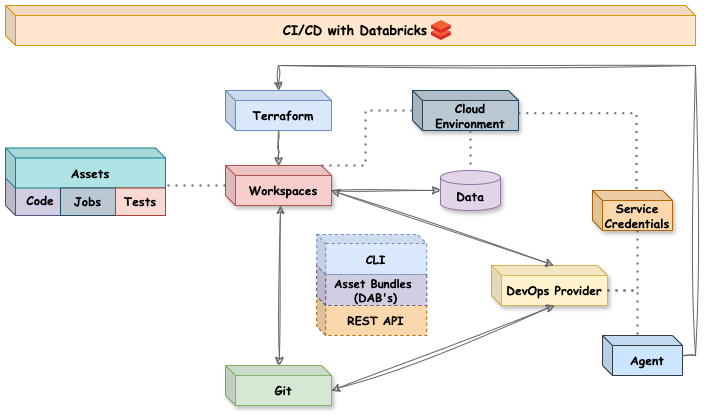
Environments: In Databricks, environments are represented by workspaces that connect code, compute resources, and data. These workspaces serve as isolated stages (e.g., dev, test, prod) where different versions of your pipeline can be tested and deployed.
Code-based Assets: These include code files, notebooks, models, jobs, clusters, libraries, and other resources stored within Databricks workspaces. These assets form the logic and orchestration of your data pipeline.
Data Assets: In addition to the code, pipelines rely on data assets — data files, tables, or streams that reside in storage systems and interact with the pipeline. Managing these assets is a unique challenge for data pipelines as the data itself must be consistent and appropriately versioned to maintain reliability in testing and production.
CI/CD Pipelines: The automated processes that manage the flow of both code-based and data assets between environments. These pipelines execute tests, validate configurations, and deploy changes from one workspace to the next, ensuring consistency and avoiding troubles in production environments.
The challenge lies in organizing these components in a way that addresses all the theoretical challenges we’ve discussed. Ideally, we also want to automate as much as possible, which requires representing our resources as code and storing them in Git for version control and collaboration.
The initial Git integration in Databricks provided a way to sync notebooks with repositories, offering basic version control. However, in 2021, Databricks introduced “Repos,” which allowed entire Git repositories to sync directly as workspace folders, significantly improving collaboration and management. This integration also enabled users to execute essential Git commands directly from the workspace UI, streamlining the development process. With the rebranding of “Repos” to “Git Folders” teams can now sync repositories outside of the dedicated “Repos” section in the workspace.
While Git handles version control, managing environments and deploying assets require additional tools. Alex Ott provides a very good overview and comparison in his blog posts: Databricks SDKs vs. CLI vs. REST APIs vs. Terraform provider vs. DABs and Terraform vs. Databricks Asset Bundles
Here’s a short summary:
Databricks CLI: A command-line interface for interacting with Databricks workspaces, allowing automation of tasks such as deploying code and managing resources.
REST API: Provides programmatic access to Databricks functionalities, enabling integration with other tools and services.
Databricks Asset Bundles: The official solution for managing code-based assets in CI/CD workflows, facilitating the packaging and deployment of notebooks, libraries, and other resources.
Terraform: Recommended for managing workspaces and cloud infrastructure, Terraform allows for Infrastructure as Code (IaC) practices, ensuring consistent and repeatable environment setups.
Recommended CI/CD Approach for Databricks
By using Databricks’ Git integration along with the tools mentioned earlier, there are several options for setting up CI/CD, some of which don’t even require an external DevOps provider. In theory, we could sync each dev-test-prod branch to its corresponding workspace (one workspace per stage) and use the REST API to update the folders in the upstream workspaces once tests and merges run successfully.
However, in a data pipeline, code and logic aren’t the only assets to manage; we also have jobs, clusters, models, libraries, etc. The issue with the approach described above is that only the code would be synced to the right environment. Other assets would follow a separate lifecycle. While their creation and management can be automated through the CLI or REST API, we prefer a centralized solution where both code and assets can be managed together. Ideally, this would allow us to deploy the same assets with different configurations to the associated environment from a single, centralized instance.
This is exactly what we can do with Databricks Asset Bundles. In the image below we can see the recommended development approach from Databricks using them.
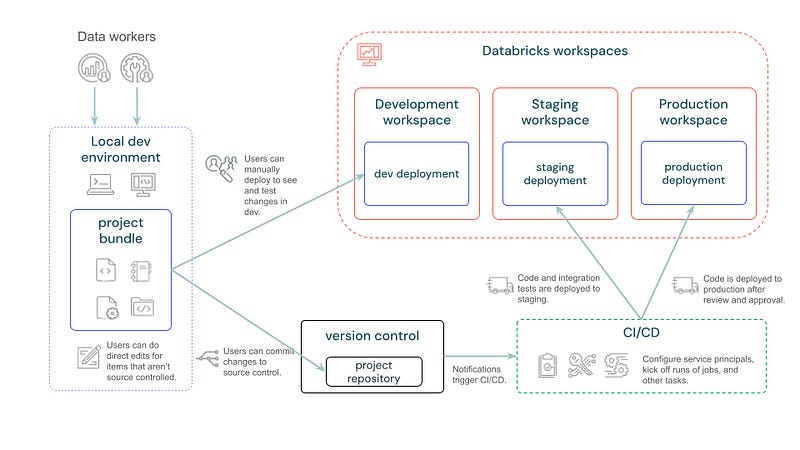
Let’s have a look at how they are supposed to work:
Development and Testing: Developers work locally or in development workspaces. They can switch around, use the workspaces for writing the processing logic and an IDE to define the YAML’s for other assets such as jobs. Then they can use the Databricks CLI to test the deployment of assets to the development workspace with a simple: databricks bundle deploy -t dev
Version Control Commit: Once code is ready, changes are committed to the version control system, and after manual approval, merges trigger the CI/CD pipeline.
Automated Pipeline Execution: The CI/CD pipeline automatically deploys the code to a test environment where tests can be executed in the form of jobs also using the Databricks CLI and Asset Bundle capabilities: databricks bundle run -t test <name_of_test_job>
Progressive Deployment: Upon successful testing in the test environment, the assets are deployed to the production environment.
For hands-on demonstration of these capabilities, I would encourage you to check out the following documentation and videos:
From Alfeu Duran:
From Dustin Vannoy:
From Databricks:
From Microsoft:
How to Set Up a Azure DevOps for Databricks
Setting up a DevOps provider for Databricks involves a few key steps, regardless of which DevOps platform you use (e.g., Azure DevOps, GitLab, GitHub Actions). While each provider has its own syntax for defining CI/CD pipelines, the overall process remains pretty much the same.
1. Agent Setup
Every CI/CD pipeline requires an agent, which is responsible for executing the tasks defined in the pipeline. The agent can either be:
A managed, serverless service provided by the DevOps platform itself (e.g., Azure DevOps-hosted agents, GitLab shared runners).
A self-hosted virtual machine (VM) that you control, which may be more suitable for complex configurations or specific environments.
The agent must have access to the code repository (such as GitHub, GitLab, or Azure Repos) where your project is stored. This allows it to pull the latest code during the build and deployment stages.
2. Cloud Service Provider Connection
After the agent is set up, it needs access to your cloud service provider — Azure in this case — to manage the Databricks workspaces. To do this, you’ll need to:
Install the necessary cloud CLI tools (Azure CLI in this case) on the agent.
Configure a connection to the cloud provider by retrieving the credentials of a service principal or managed identity. This identity should have the necessary permissions to manage Databricks resources (such as creating and updating clusters, jobs, etc.).
Once this connection is established, the agent can authenticate with Azure to retrieve the required tokens or credentials to operate.
3. Configuring the Databricks CLI
With cloud access configured, the next step is to configure the Databricks CLI. This is done on the agent using the credentials retrieved from Azure. The Databricks CLI allows you to interact with the Databricks environment programmatically. You can use it to:
Deploy code and notebooks that were synced from your Git repository using the Asset Bundle capabilities.
Create and update clusters, jobs, libraries, and other Databricks assets.
4. Deployment and Workspace Operations
Once the Databricks CLI is set up on the agent, you can automate the deployment process. The agent pulls the code from your Git repository and uses the Databricks CLI to:
Deploy the code to the correct environment (e.g., dev, test, or prod workspaces).
Perform operations within the Databricks workspace, such as running jobs, creating clusters, or updating libraries.
This setup ensures that the pipeline can continuously integrate and deploy code changes while maintaining consistency across different environments.
How to Test for Data Engineering CI/CD
Testing data engineering solutions is complex due to the close interaction between code and data. Here, we’ll explore two essential types of testing that should be included in any CI/CD process for Databricks:
Unit Tests
Unit tests focus on validating the behavior of individual components or functions within the code. These tests ensure that each small piece of logic works as intended, independent of external factors like data sources or dependencies.
For data pipelines, unit tests might include testing individual transformation logic, ensuring that data is processed correctly or that business rules are applied as expected. Functions such as data cleaning, aggregation, or mapping should be covered in unit tests.
For concrete examples and best practices for developing unit tests on Databricks I would recommend the following two resources:
- Unit testing for notebooks (official documentation)
- Best Practices for Unit Testing PySpark (Matthew Powers)
Integration Tests
Integration tests validate the entire data pipeline in an end-to-end scenario. These tests ensure that all components work together and that data flows correctly from ingestion through to final processing and storage.
In a Databricks pipeline, an integration test could involve running a complete data processing workflow, starting from data ingestion, applying transformations, and storing the final output in the target system.
Implementing these tests poses several challenges:
Data State Management: Data changes during testing can affect the consistency and reliability of test results.
Production Parity: Accurate testing is difficult without an environment closely resembling production, highlighting the importance of maintaining similar configurations across environments.
How to Handle Test Data in Databricks Workspaces
A key challenge when testing data pipelines is determining how to manage test data. Unlike unit tests, which operate on a small scale, integration tests often require data that mimics production conditions. Here are some considerations and strategies for managing test data:
1. What Data to Keep in the Test Workspace?
One option is to use a static dataset that represents recent production data, such as a snapshot from the last month. This allows you to run tests against realistic data without directly impacting production systems. However, the data needs to be representative enough to catch potential edge cases and issues. What’s more is that static datasets can become outdated, and they might not reflect the nature of real-world data, making it difficult to catch all potential issues.
2. Where Does the Integration Test Start?
Deciding the entry point for your integration tests is essential:
Should the test begin at the data ingestion stage? If so, you will need a static dataset available at the source, mimicking real-time data ingestion from external systems.
Alternatively, the test could start further along in the pipeline, focusing on processing and transformation.
Testing ingestion requires either a mock source system or static data in the source, adding complexity to the test environment.
3. How to Manage Changing Datasets During Tests?
As integration tests run, the data in the pipeline will change (e.g., transformations will be applied, or new records might be added). This raises a critical question: How do you reset the data after each test run?
One approach is to use smaller, in-memory datasets during testing to simplify data management. These datasets can be embedded in the code itself, allowing you to test each processing stage (e.g., bronze to silver) in sequence. While this approach reduces the need for resetting datasets after each run, it may not fully capture the complexity of real-world data, limiting its effectiveness.
Another approach is to create snapshots or backups of test datasets before each run, allowing you to restore the data after each test execution using capabilities such a Delta Lake History.
Overall, managing test data, deciding where the integration test begins, and handling dynamic datasets are significant challenges that require careful consideration to ensure reliable tests.
Conclusion
Implementing CI/CD for data engineering, particularly on platforms like Databricks, has made significant progress over the last couple of years. Traditional CI/CD models, primarily designed for software development, struggled to handle the intricate interdependencies of code, data, and compute resources that define modern data pipelines.
Today, the landscape for CI/CD in data engineering is much more mature and stable. While there is still no one-size-fits-all solution, organizations now have access to a wide range of tools that enable them to build reliable, scalable pipelines that manage both code and data effectively. However, there is still much room for improvement as the field continues to evolve.
I hope you enjoyed the article!
All the best,
Eduard