
Supercharging Performance with Partitioning in Databricks and Spark (Part 3/3)
Why Every Data Engineer Needs to Understand Partitioning!

This is the third article out of three covering one of the most important features of Spark and Databricks: Partitioning.
Part 1 covered the general theory of partitioning and partitioning in Spark.
Part 2 delved into the specifics of table partitioning and we prepared our dataset.
This chapter will combine everything we have learned so far. We will carry out some performance comparisons and actually see the impact of all the theories we have covered
Impact on performance
I have often seen that partitioning and file size can have a tremendous impact on the performance of our workflows and just taking a closer look at them can reduce both processing time and costs significantly:
If we have too many small files we will create a lot of overhead
If the file size is too large it can lead to skewed data and imbalances in the workload
Why is all of this important?
Let’s look at a couple of read and write operations comparing different setups.
I will select a random subset of our data for the months of June and May in 2018 and add some other filters and compare the read times.
Afterwards, I will delete the subset from all tables and merge them back and compare the write times.
Reading: Unpartitioned vs Partitioned vs Partitioned_O (Target File Size + Optimized )
1. Unpartitioned
%python
spdf_data_unpartitioned = spark.sql("""
SELECT
*
FROM
optimization.data_unpartitioned
WHERE
(puYearMonth = 201806 OR puYearMonth = 201805)
AND totalAmount > 6
AND vendorID = 1
AND tipAmount > 2
AND tripDistance > 2""")If we open up the Spark UI and take a look the associated SQL query we can see exactly how long it takes to compute the results. I also expand the details in the query plan so we can also understand why we have differences in duration even if we select the same data:
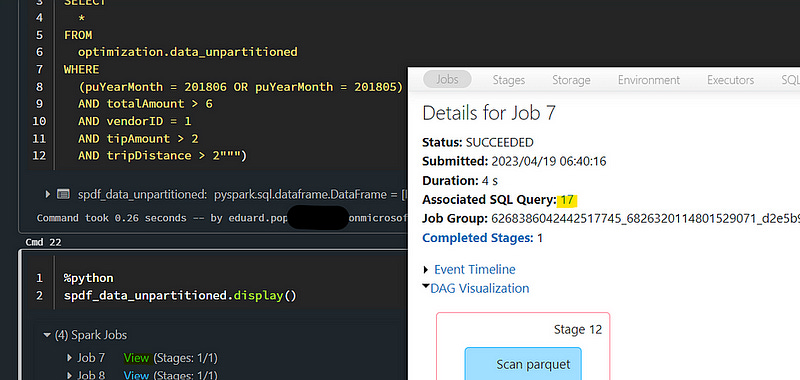
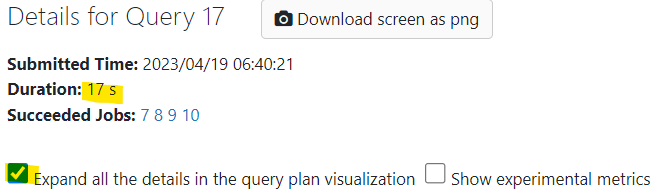
2. Partitioned
%python
spdf_data_partitioned_year_month = spark.sql("""
SELECT
*
FROM
optimization.data_partitioned_year_month
WHERE
(puYearMonth = 201806 OR puYearMonth = 201805)
AND vendorID = 1
AND totalAmount > 6
AND tipAmount > 2
AND tripDistance > 2""")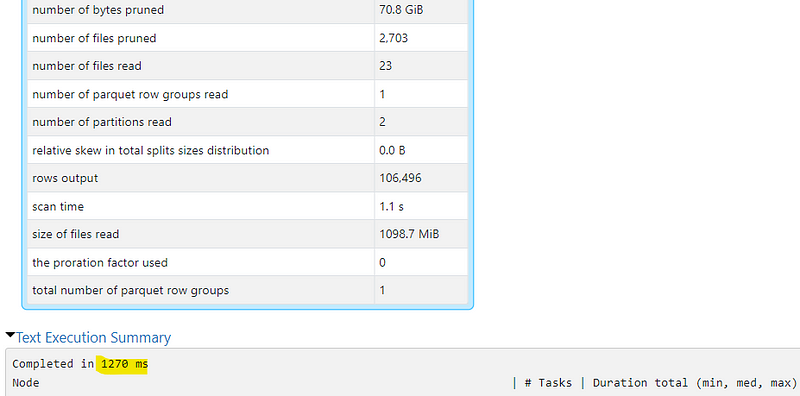
3. Partitioned_O
17 s vs 1.2 s vs 1.1 s
We see a significant difference between the different setups. It’s important to note that we are working with quite a “small” data size and the overhead still plays an important role but imagine the effects on a large scale using one or the other setup
So why are these so different?:
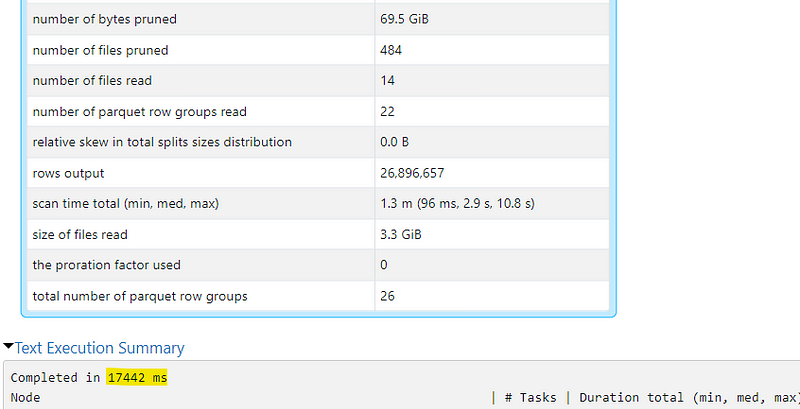
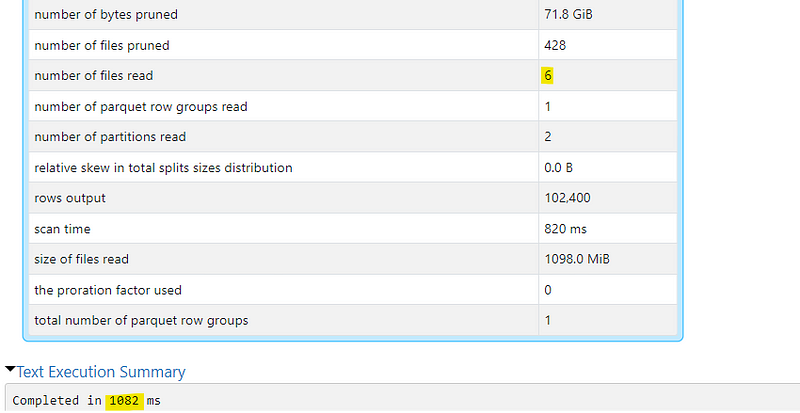
The unpartitioned setup takes the longest. We can see that it had to read 14 files summing up to 3.3GiB to find the records we were searching for. Since we do not partition, our records can be scattered accross multiple partitions which accumulate into quite a large amount of data that needs to be parsed
The partitioned but not optimized setup took half as long. We see that it was able to reduce the amount of files it needed to read from 3.3GiB to around 1.1 GiB. However, in that setup it still had to read 24 files
The partitioned and optimized setup was the fastest. Around 17x faster than the unpartitioned setup and just slightly faster than the partitioned but unoptimized setup. We can see that it had to read about the same amount of data as in the partitioned setup but it only had to access 7 files instead of 24
Writing: Unpartitioned vs Partitioned vs Partitioned_O (Target File Size + Optimized)
First, I want to create a table containing the subset of the data, so I can merge it back into our tables again after deleting
%sql
CREATE
OR REPLACE TABLE optimization.data_subset_unpartitioned USING DELTA
AS
SELECT
*
FROM
optimization.data_unpartitioned
WHERE
(puYearMonth = 201806 OR puYearMonth = 201805)
AND totalAmount > 6
AND vendorID = 1
AND tipAmount > 2
AND tripDistance > 2Second, I also want to use partitioning pruning to reduce the amount of data we need to work with in our target table as much as possible.
In our case, we can do this by retrieving the max and min of the puYearMonth. It does not make sense to scan the entire table and look for matching Ids. We only want to look at the data in our specific timeframe, in our case, May and June 2018.
1. Unpartitioned
2. Partitioned

3. Partitioned_O

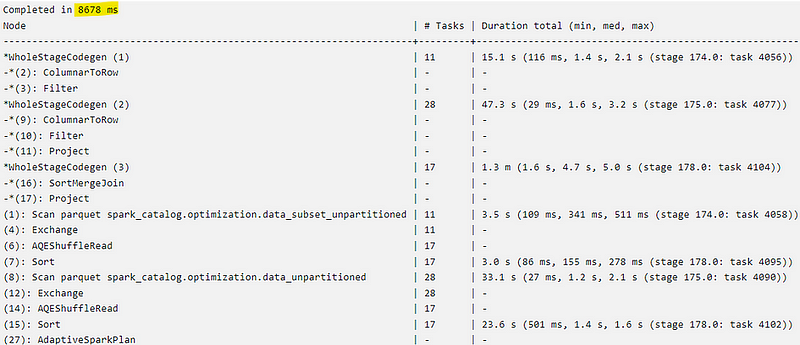
I also ran the examples without pruning and each merge takes significantly longer but our partitioned and optimized table actually performs the best
1. Unpartitioned
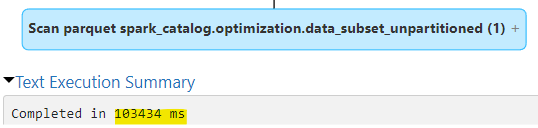
2. Partitioned
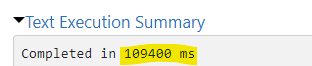
3. Partitioned_O
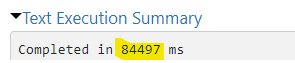
In conclusion, we can see that for merges, our custom partitioning actually decreases the performance if we also use pruning. In the query plans, we can also see that for the unpartitioned table, Databricks is taking advantage of Adaptive Query Execution (AQE) which was introduced with Spark 3.0 and Databricks 7.0
For our custom setups, Databricks is not able to use this automatic optimization in this instance. Therefore, if we interfere with the default settings, we might loose out on features like this
In another article in the series I will look into what we need to optimize for merges in Databricks but for now I just wanted to showcase the trade-offs we are making
Shuffle and Partitioning
When working in Spark, one operation we want to minimize is shuffle. Shuffle operations are necessary when data needs to be redistributed across partitions to perform a specific operation or transformation
This process is resource-intensive and time-consuming, as it requires the exchange of data between executor nodes in the cluster. Consequently, minimizing shuffle operations is crucial for optimizing the overall performance of processing pipelines
One example for when a shuffle could be necessary is a group by. Let’s compare how long it takes to group by our partitioning month for each setup
1. Unpartitioned
%sql
SELECT
puYearMonth,
max(tipAmount)
FROM
optimization.data_unpartitioned
GROUP BY
puYearMonth
2. Partitioned
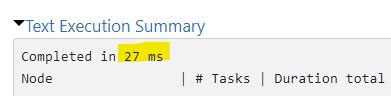
3. Partitioned_O
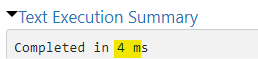
We can see some significant differences. As each month has it’s own partition in the partitioned setup, we do not need to exchange any data between the partitions and it’s much faster.
Conclusion
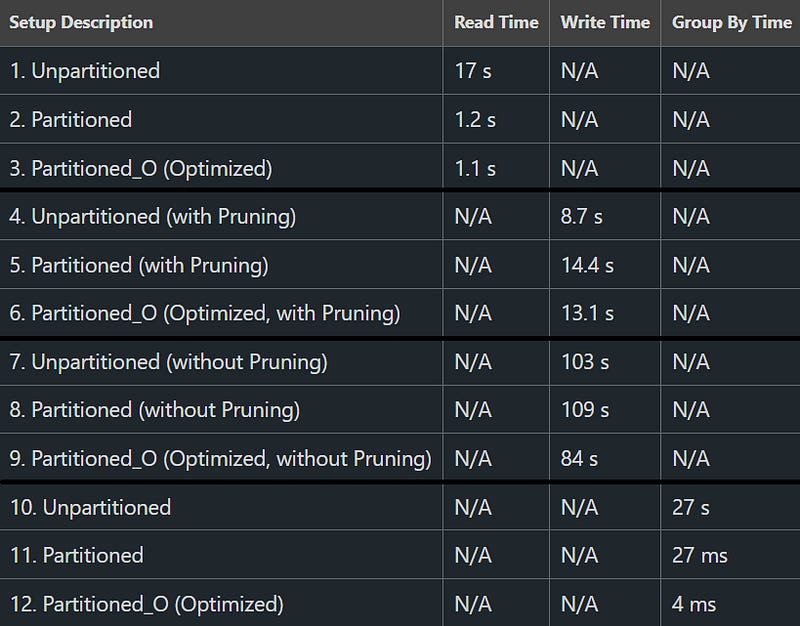
These are just a couple of examples of how partitioning and file sizes impact performance.
There are other important details to take into account, but I believe the topic is worth investigating since we have the potential to save a lot of computing resources, time, and money.
Thank you for reading!