
Creating Business Value with Databricks: The Role of Solution Architects
Bridging the gap between stakeholders and data teams to bring valuable data solutions into production

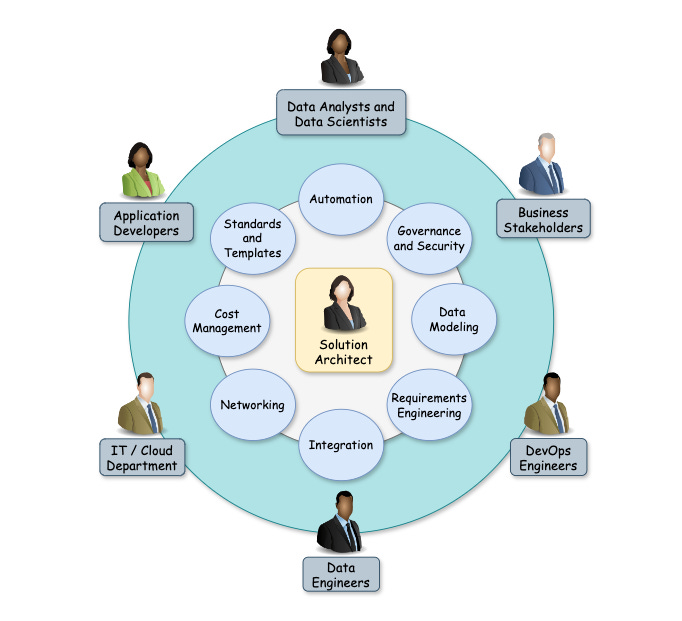
Over the past 5+ years, I have worked as a data engineer and data/solution architect on two major migrations from on-premise systems to Azure. I’ve also implemented numerous use cases for some of the largest companies in manufacturing, automotive, transportation, and consumer goods. During this time, my primary responsibility has been data engineering with Databricks and Azure.
So what does a solution architect actually do? In my view, a solution architect is responsible for managing all the activities needed to bring a data solution into production, except for writing the code. This includes things such as requirements engineering, data modeling, defining integration patterns and others.
However, many companies do not have dedicated solution architects. As a result, data engineers often need to handle a wide range of responsibilities beyond just writing data pipelines and eventually become data architects themselves.
But getting things into production is not the only thing we want to achieve. The solutions also need to deliver business value. In this article, I will share everything I have learned over the years about all the key aspects we need to consider when developing a valuable data engineering solution with Databricks.
Requirements Engineering
The goal of a data engineering solution is to ultimately provide the right stakeholders with the data they need, in the format they need, when they need it.
In practice, determining how to achieve this is more complicated than some might expect, given the many moving parts involved. In consequence, translating business requirements into technical solutions is one of the first and most important responsibilities of a solution architect.
As an all-in-one data platform, Databricks can be used for many different purposes and in various different ways. Some use it within a narrow scope, while others heavily rely on it for a wide range of tasks. It’s important to determine why and to what extent we plan on using Databricks based on the business requirements, so that we can make sure all efforts are focused on reaching those goals.
Therefore, we need to clearly define what the business wants to accomplish and what success in reaching those objectives looks like. To do this, we need to start by answering a couple of questions:
Business Questions
What are the primary business goals? Do we want to increase revenue, reduce costs, improve customer satisfaction, or something else?
How does data support these goals? What specific metrics or KPIs are we looking to improve or monitor?
What does success look like? How will we measure the effectiveness of the solution in achieving the business objectives?
Project Longevity: Is this a project with a clear scope and end date, or will development continue indefinitely?
Organisational Considerations
The size, expertise, and role of the data engineering team, along with the data maturity and budget of the company, also significantly impact our approach. We need to consider:
Team Involvement: How many people will be working on each use case, and what are their roles and expertise levels?
Requirements Gathering: How well can the team define and provide requirements? Will we need to extract and define every detail, or is the team capable of providing well-defined specifications?
Budget and Deadlines: Are there strict budget constraints and hard deadlines that we must adhere to?
High Level Technical Questions
Scope of Use: Are we using Databricks solely for data engineering, or will it also be used for data science, machine learning, and data analytics? Additionally, is Databricks being used for BI/reporting and analytics, or as the backend for a data application?
Development Scope: Are we developing Proof of Concepts (PoCs), Minimum Viable Products (MVPs), or production solutions right from the start?
Execution Environment: Will Databricks be used as an “execution engine” for specific workloads or as a comprehensive development environment?
Platform Utilisation: Is this the first and only use case for Databricks, or do we intend to use it as a platform for multiple use cases?
Detailed Technical Considerations
Once we have clarity on the “big” reasons for using Databricks and the organisational frameworks, we can go deeper into the details:
Use Case Types: What kinds of use cases are we going to implement? Are they batch processing, streaming, Online Analytical Processing (OLAP) or Online Transactional Processing (OLTP)?
System Criticality: How critical are these systems? Are they directly integrated into production processes, such as manufacturing?
Greenfield vs. Brownfield: Is this a greenfield data use case, or do we need to rely on and integrate with existing structures?
Source Systems: What source systems are we connecting to? Are they streaming data sources, RDBMS, cloud-based, or on-premise?
The answers to all of these questions and others will give us the foundation for the entire project. I’ve seen initiatives that start without answers to these questions often face significant challenges down the road, leading to delays, scope creep, and sometimes failure to deliver the intended value.
Setting Priorities Based On Requirements
In a perfect world, we would have clear requirements, complete data covering all possible edge cases, and perfect templates where we could simply insert the code and it work would indefinitely. The source application would never break or change, and everything would function smoothly. However, anyone who has ever developed a data solution knows that this is far from reality.
I focus so much on understanding the requirements and the organisational setting because every project is different and requires a custom approach. This means that we also need to make trade-offs and balance competing demands. When developing a data engineering solution, I typically consider several key factors, as shown in the image below:
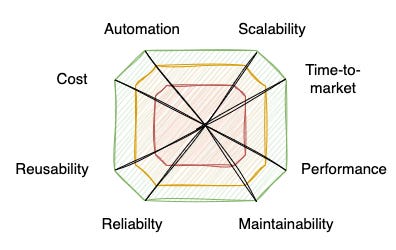
A technical solution must meet the minimum requirements in all aspects, but achieving the highest levels in every area simultaneously is simply not feasible. Determining how to set priorities based on interactions with stakeholders and the business’s goals will be the second important responsibility of solution architects.
Integrating Databricks into the Enterprise Architecture
While most of the content so far has focused on business stakeholders, particularly management, there are other departments that we need to align with. Especially in larger enterprises, IT and data teams are usually separated and ensuring a good collaboration between the two is in my experience crucial for the success of any data initiative.
When we talk about integrating Databricks into the enterprise architecture and working together with the IT department, there are several areas we need to take into account:
Integration into Data Landscape
Databricks can be an all in one data platform. However, the reality is that for most enterprises, Databricks will be part of a broader data architecture with many other tools and services.
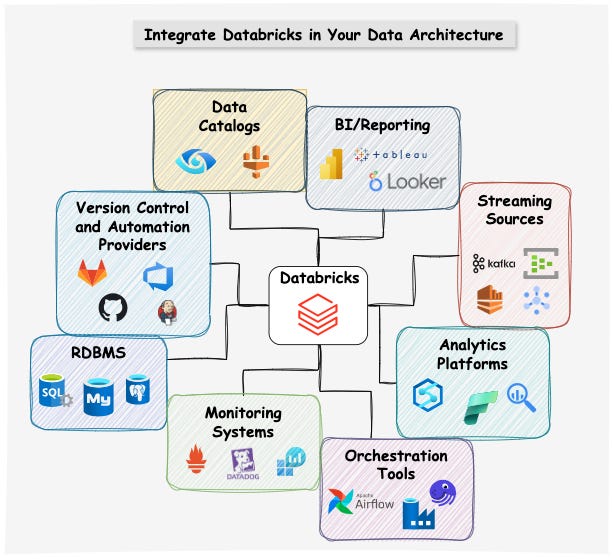
This is why learning how to integrate Databricks with other systems will be one of the most important tasks for data engineers / solution architects, in addition to learning how to work with the platform itself.
The good news is that Databricks has excellent built-in integrations with many of the most common technologies. If an integration is not available out of the box, the API/CLI and SDK offer the resources you need to create custom solutions.
In the image above and in this LinkedIn post I have gathered some of the top tools you need to consider and resources to help you integrate Databricks into your data architecture:
Integration into Network Architecture
Databricks workspaces are the interfaces we use to connect code, storage, compute, and data. Therefore, Databricks needs to be able to connect to other systems within the organisation, whether they are cloud-based or on-premises resources.
Data engineers and solution architects might not need to set up all the networking configurations, but they should be familiar with the Databricks architecture and the available options so they can provide guidance to the IT department.
In Databricks we have several different options to configure private connectivity for both front- and backend as well as different setups for all-purpose and serverless clusters.
For a comprehensive overview of how networking in Databricks works, you can read my in-depth article on the subject:

Defining Operations Model for Databricks
Even though Databricks is a managed service, using it in an enterprise context is not as simple as just creating a default workspace. In order to be compliant with corporate standards and ensure a smooth operation of the platform, we need to establish who defines and implements…
… the Infrastructure as Code (IaC) for workspaces and associated resources such as networking resources, storage accounts, key vaults and others
… workspace and cluster policies
… CI/CD and automation processes
… integration into corporate network
… integration with IDM (Identity Management) providers together with roles and permission models
… logging and monitoring
… security standards
… backup and recovery plans
Solution architects need to understand these aspects, even if they do not implement everything themselves. To bring a solution into production as quickly and reliably as possible, they need to be able to provide guidance to the IT department and collaborate with them, as it will most likely be a shared effort.
Bridging the Gap between Stakeholders and Users
Solution architects need to be the link between the business/IT and the developers/end-users of a data solution. This requires them to consider both the organisational and technical context and then design a solution that meets everyones requirements (or at least try to).
While the IT department and business stakeholders play critical roles as enablers and supporters of data initiatives, it’s the developers who build and the users who utilise the data solutions, each interacting with the data and platform in different ways. Solution architects must consider their requirements and design platforms that enable them to perform their jobs as well as as possible:
Defining Development Approach, Standards and Templates
A well-defined development approach is essential for maintaining consistency and quality across the entire platform. This includes establishing coding standards, development templates, and best practices that guide how data pipelines are built on Databricks:
Coding Guidelines: Clear guidelines for writing clean, efficient, and scalable code.
Development and Resource Templates: Pre-built templates for common use cases such as batch and streaming pipelines and other artefacts such as clusters and jobs.
Utility Functions: If there are common tasks that need to be performed repeatedly, it's worthwhile to consider creating custom utility functions or libraries to avoid redundant effort.
Best Practices: Establishing guidelines for optimising performance, managing resources, and ensuring data quality.
Designing Environments and Policies
To develop high quality data solutions we need different environments to develop, test and run our data solutions. Each environment will have a different purpose and will be configured differently.
For a complete overview of what we need to consider when we design our Databricks environments and the development approach, you can check out my full article on the topic:

In essence, solution architects need to consider how to configure each environment with regard to storage, code, data, compute, governance and security. Below are some general recommendations, but the solution architect must determine the exact configuration for each project, taking into account all business requirements.
Storage:
Development: Use cost-effective storage options, and consider using mock or sample data to avoid the risk and cost of working with real data.
Test: Mirror production storage configurations as closely as possible, including using representative datasets to simulate real-world conditions.
Production: Opt for high-performance, redundant storage solutions that ensure data durability.
Code:
Development: Enable flexibility for experimentation and iterative coding, with integrated version control for collaborative work.
Test: Ensure code is stable and ready for production by running it through comprehensive testing pipelines.
Production: Only tested and validated code is deployed. All code should be version-controlled, and no manual changes should be made directly in production.
Data:
Development: Use sample or anonymised data to avoid confidentiality issues and reduce load on production systems.
Test: Utilise a full or representative subset of production data to test the solution under realistic conditions.
Production: Manage and secure live, up-to-date data, with strong access controls to protect sensitive information.
Compute:
Development: Allocate smaller, flexible compute resources that can be easily scaled up or down for development needs.
Test: Match the compute resources with production settings to accurately assess performance and stability under load.
Production: Use dedicated, reliable compute resources with optimised settings for performance, avoiding shared or spot instances to ensure consistency.
Governance and Security:
Development: Implement basic governance and security measures, with more lenient access controls to facilitate collaboration.
Test: Reflect production-level governance and security settings to ensure compliance and identify potential vulnerabilities.
Production: Enforce strict governance, access controls, and security protocols, including encryption, monitoring, and regular audits, to protect data and system integrity.
For a complete overview on Governance in Databricks, I recommend checking out my in-depth article:

Designing Automation
The amount of time that can reasonably be spent on automation depends significantly on the requirements and scope of the project. Building full-scale automated templates for five use case archetypes and representing every single resource and policy as IaC can be excessive overhead if we only intend to use Databricks for a few simple use cases.
However, if we need an incredibly stable and reproducible solution, it’s essential to ensure that the data pipelines and other components can be tested, deployed, and maintained with minimal manual intervention.
Therefore, solution architects must determine when, how, and to what extent they need to collaborate with Data/DevOps and IT engineers to define the following:
CI/CD Pipelines: Automating the build, test, and deployment processes to ensure that changes can be released quickly and reliably.
Infrastructure as Code: Managing infrastructure resources through code, enabling reproducibility and version control.
Automated Testing: Implementing tests that automatically validate the functionality and performance of data pipelines.
Other Responsibilities
Beyond the core responsibilities of solution architects, there are many other aspects that may become relevant depending on the circumstances. Each of these topics would require its own dedicated article, so I will briefly mention some of them here and hope to cover them in more detail in the future:
Designing data models for data lakes: Ensuring data is organised, stored, and accessed efficiently, adapting legacy patterns to new developments.
Designing cost management frameworks: Aligning cost strategies with financial goals, optimising resource usage.
Adopting new platform features: Evaluating feature stability and business impact before implementation.
Integrating Databricks with other analytics platforms: Determining when to use Databricks versus another tool and designing cross-system pipelines accordingly.
Designing data consumption patterns: Optimising user access, data delivery, performance, and scalability to meet end-user needs
…and many others
Conclusion
No article or book can cover every topic a solution architect needs to know. It takes years of experience to gain a comprehensive understanding and even more to effectively guide implementation. Even then, no single solution architect can handle every aspect of data architecture development. This is why collaboration with other solution architects, data engineers, data scientists, analysts, networking teams, IT, and governance experts is essential and should be a core skill for every solution architect.
However, having a high-level understanding of all the necessary components beyond core pipeline development is crucial for bringing data engineering solutions into production and creating real business value.
While this article has focused on Databricks as the tool of choice, the principles discussed can be applied to adopting any other tool or platform in your data stack.
I hope you enjoyed the article and in case you found it useful, consider sharing it with others who might appreciate it!
All the best,
Eduard