


Azure Databricks in the Enterprise Context: Cost Management
9 Ways to Optimise Your Databricks Costs You Won't Find in the Documentation


Preface: Databricks in the Enterprise Context
Databricks can be an amazing platform for developing solutions for data engineering, data science, and data analytics. It abstracts many of the cumbersome infrastructure tasks required to manage a self-hosted Spark environment and offers numerous additional capabilities beyond an execution environment for Python, Scala, R, or SQL code.
For personal projects, it is easy to create a Databricks instance, set up a cluster, and get straight to development.
However, in an enterprise context, there are many additional topics that are critical for gaining permission to use Databricks and then using it effectively:
Networking:

Governance:

Cost Management
Monitoring
DevOps and IaC
Data Quality
and so many more…
Since first working with Azure and Databricks in 2019, I have greatly enjoyed building solutions on both platforms and consulting others on how to do it too.
In this series, I present my own learnings, summarise the documentation in a structured way, and identify critical points companies need to consider.
Right from the start, I have to say that the theory for cost management is very well explained by the Databricks and Microsoft documentation, as they are well aware that it is a concern they must address.
Therefore, the purpose of this article is NOT to reiterate the same information. If you want to find out about cluster policies, how costs are calculated, the different runtimes, auto-scaling etc. you can find the links to the documentation and official videos in the references and resources section below.
Instead, I want to share 9 considerations, ideas, and features based on my experience that are not so obvious but have a significant impact. These also take into consideration business, organisational and perhaps also human factors.
1. Don’t calculate you costs in DBU’s
Databricks costs are comprised of three (or four) elements: consumption, cloud infrastructure, and cloud storage. Optionally, other custom cloud services related to Databricks, such as private endpoints and firewalls, can also contribute to the overall cost.
Consumption in Databricks is measured in DBUs (Databricks Units), and you might be tempted to say: “Oh yeah, it’s only 4 DBUs, so approximately 2$ dollars.”
However, the cost of the same DBU can vary significantly depending on the workload you are running. As seen in the image below, in the standard tier, 1 DBU for a Jobs Compute costs $0.15 per hour, while a DBU for a Serverless SQL compute costs $0.91 per hour!
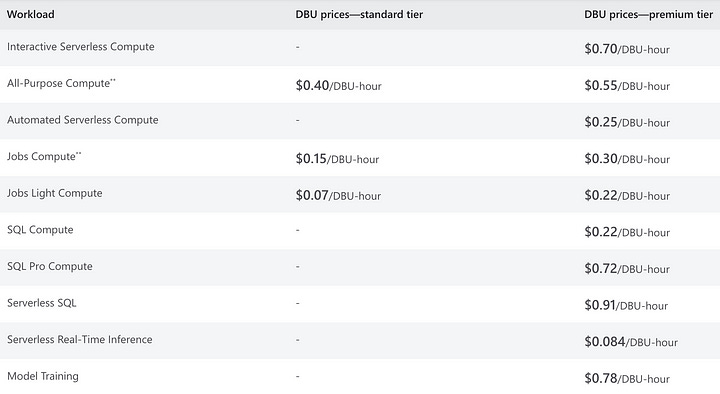
This is a sixfold difference that I don’t see many people talk about. This is why it is not really possible to simply calculate your costs in DBUs; you always need to multiply your DBUs by the workload type.
With Unity Catalog, we now have system tables available that easily enable us to see the DBU consumption. Along with the list price table, we can now actually calculate our costs in real currency and create some detailed reports based on the data.
2. Take a look at your pricing tier
As seen if the first image, the are significant differences between a premium and a standard Databricks instance. For most enterprises, there is simply no way around using premium instances for productive workloads if they want to comply with networking and governance requirements while also taking advantage of the newest features that Databricks provides.
The standard tier that Databricks provides is essentially just a managed Spark environment without many of the newest features such as SQL warehouses, Delta Live Tables or Unity Catalog. Furthermore, the standard tier does not support other advanced infrastructure and security features such as private connectivity. However, for certain workloads, if the guidelines allow it, it might be possible to actually combine the two and use standard tiers for development and premium tiers for production.
3. Don’t use the DBFS (Databricks File System)
Apart from the fact that Databricks themselves say that you shouldn’t store production data in DBFS, there is also a cost consideration to be made.
When we create a Databricks resource in Azure, it automatically provisions a managed resource group where the virtual machines for the clusters will be created. Depending on the networking setup, this resource group will also contain different resources required for Databricks to operate.
This resource group also contains a storage account where the files stored on the DBFS (Databricks File System) will also be saved. Managed tables without an explicit location will be created in this storage account.
Now, this storage account is automatically created with geo-redundant storage and the access tier is hot. These two configurations cannot be modified.
Even though it doesn’t seem like much, the difference between $0.01 per GB for cool, locally redundant storage and $0.039 per GB for hot, geo-redundant storage (which you might not actually need) can amount to several hundreds or thousands of dollars per month if you also need to store your data for long periods of time. Then, you may want to implement archive policies to benefit from the cool storage tier, which requires storing your data in your own storage accounts.
In my opinion, all data should be kept in storage locations we have full control over, which also helps us avoid accidental deletion of the actual data.
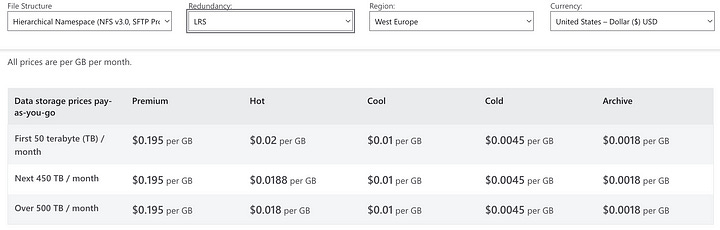
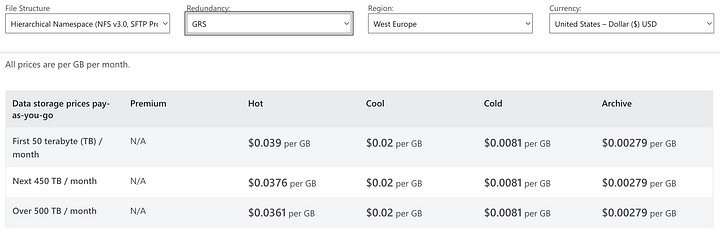
4. Create archive policies
The previous images also show that there are significant cost differences between hot and cold storage. Even though it might be tempting to label storage costs as neglectable in a cloud environment, they do add up.
If you work with large amounts of data that need to be stored for a long amount of time, it is worth thinking about how to move old data in a cheaper storage tier if they are not frequently needed. Important to mention is that Databricks does currently not support non-standard storage tiers such as Archive.
5. Use the appropriate clusters for development
I cannot count the number of times I have seen people using disproportionately powerful clusters for tasks that do not require them.
You do not need a large cluster to work with small amounts of data, write functions, or run unit tests. The cheapest cluster in Azure Databricks currently costs around 0.75 DBU, which is approximately $0.41 per hour, and with that, you have all the features of Databricks available, can use the proprietary features, have your connections to source systems, etc.
This is why I find it difficult to agree with the argument that development should happen locally to avoid high consumption costs. Even if there is a minor issue due to the local environment not matching the Databricks one, the labor costs to resolve it will likely exceed the cluster costs.
In essence, just because resources are available does not mean we should abuse them. For example, I usually create two clusters, one very small one for simple tasks, and a more powerful one for testing scenarios closer to production.
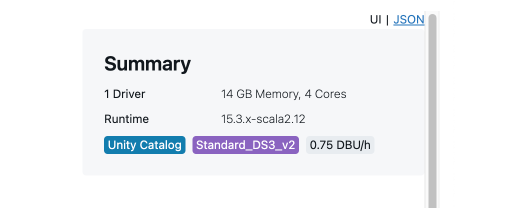
6. Develop abstract logic in local environments
Now, even though I am not a big fan of this approach, if you can establish a local development workflow that works for you, you can avoid a significant portion of the cluster costs for development.
It is possible to create local environments with Spark and Delta to develop and test basic functionality and then only push the code to Databricks for integration and system tests.
With this approach, you can work in your favourite IDE, and it also forces you to create a clear specification that can be broken down into small standalone functions.
However, there are several drawbacks to this approach that usually make it less appealing for me, but the cost benefits might outweigh them in your case.
7. Do not use an auto-termination time below 15 minutes
Even though it might be tempting to set very low auto-termination times for clusters to avoid idle times, it doesn’t make sense to set them below 15 minutes, as cluster start-up times can take up to 5–7 minutes if the nodes you are requesting are in high demand.
Moreover, it is very frustrating for developers to be focused on writing code and then have to wait for the cluster to start up. For me, 20 to 25 minutes is the sweet spot that helps me stay productive.
8. Beware of your streams
Even with auto-termination set up, I have seen situations where notebooks ran continuously for weeks because people were experimenting with streams. They started a streaming job that was continuously monitoring the source location for some tests and then forgot about it.
In cases like this, the cluster will not stop as there are processes running, and if you have many notebooks and clusters running simultaneously, they might go unnoticed or people might think it is actually a long running test.
9. Teach before you optimise
Before optimising, creating a clear set of guidelines to help new users effectively and consciously use tools like Databricks is essential in my experience.
Of course, you can create and enforce policies regarding what users can do, set up budgets etc. and that will certainly help, but there might be cases you do not cover. Then, you’re hit with a large bill because someone was unaware of some costly functionality that you didn’t restrict.
Moreover, if you just enforce policies without helping your users understand why you are doing it, it might create frustration because they feel like they cannot use certain functionalities that would be useful to them.
I am convinced that a 30-minute awareness training for new users will help immensely compared to just imposing restrictions.
Conclusion
I started with the goal of writing a comprehensive article about cost management in Databricks but realised along the way that there are already very good articles and guides in the official documentation. Therefore, I switched to sharing some of my personal insights, which I hope will help you in addition to what is already available.
One thing I have not focused on in this article is code inefficiency. Some of the largest cost drivers are bad architectures or logic that just doesn’t benefit from running on Spark/Databricks. This is why I would place significant emphasis on educating employees to learn how to work with Databricks and Spark efficiently.
In conclusion, effective cost management in Databricks requires more than just understanding the platform’s pricing structure and features. It involves a combination of policies, monitoring, education, and experience. With this, I hope you learned something, and see you next time!